Performance¶
How memory hungry is Glass Box UMAP? How big of a dataset can you fit on a typical laptop? How much does using a GPU increase time to fit? These questions are answered on this page.
How a fit works¶
A fit has two stages. First, a nearest-neighbor graph is constructed over the input array X, capturing which points are close to which in feature space. Second, a small encoder network is trained whose loss encourages the embedding to preserve those neighbor relationships in low dimensions. The graph build runs on the CPU. The encoder runs on whichever device is selected (CPU, MPS, or CUDA).
Two implementation details govern what fits and how fast it runs. Graph construction uses pynndescent, which expects the full input array in RAM (and does not stream from disk). The resulting graph is sparse and small in absolute terms (a few bytes per edge), but the working set during the build is large. Once the graph is generated, the encoder is trained by iterating over the graph’s edges in batches, with the dataloader reading rows from the same in-memory X for every batch.
At least in principle, both stages could be out-of-core. An out-of-core nearest-neighbor library, plus a graph-aware streaming dataloader that reads rows from disk indexed by the edge list, would lift both memory ceilings substantially without changing what Glass Box UMAP does. We do not have that today, so the rest of this page measures the ceilings as they exist: a memory frontier set by the graph build, then a speed profile that depends on which device the encoder runs on.
How big a dataset fits on a typical laptop?¶
Note
The local numbers below come from a 2023 14-inch MacBook Pro with an M3 Max chip, 14 cores, 36 GB of unified memory, and the integrated GPU exposed to PyTorch through MPS. We treat that machine as a stand-in for “a typical laptop.”
Warning
A faster GPU buys you faster training (more on that in the next section), but it does not improve the memory bottleneck associated with nearest-neighbor graph construction. The graph is built on the CPU regardless of the training device, and both the input array and the graph live in host RAM.
The grid below ran the nearest-neighbor graph build on Gaussian blobs of shape (n_samples, n_features) for every cell. We measure peak resident set size (RSS), the total bytes the process holds in physical memory at the highest point during graph construction. The training loop adds a couple of gigabytes of model and optimizer state on top of these numbers, but nearest-neighbor graph construction is the bottleneck that decides what can be fit.
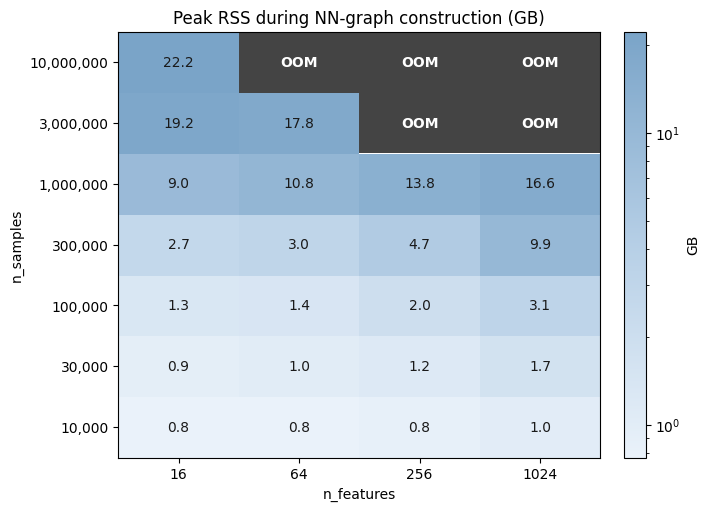
Cells in the top-right corner, where n_samples and n_features are both large, hit the out of memory (OOM) zone. Everything else shows the peak RSS the cell actually used. Read off the boundary to size your fits: roughly fifteen million points at 16 features, three million at 64, one million at 1024, and a hundred thousand at any feature count up to a thousand without breaking a sweat. Going beyond either edge needs more RAM or a different strategy.
The shape of the surface is also informative. Memory grows much more steeply along n_samples than along n_features, so doubling the number of observations is a much bigger ask of the machine than doubling the number of features.
If your dataset is too large to construct the graph, the most obvious but potentially least practical solution is to use a machine with more RAM. If that’s not possible, you could consider either projecting to fewer features before the nearest-neighbor step (see PCA preprocessing), or fit on a representative subsample and transform the rest, since Glass Box UMAP is parametric. Neither changes the underlying ceiling, but both can move you well inside it.
Speeding up training¶
The dominant cost knob in Glass Box UMAP is epochs. The encoder is a neural network that needs enough training time to actually settle on a good embedding, so reducing the epoch budget is the most direct way to make a fit take less time. Many problems converge well before the default 200-epoch budget, and you can often cut that in half or further without a measurable change in the embedding. See monitoring training for how to watch the loss curve and decide when to stop.
Reducing epochs makes a fit shorter by training on fewer examples. The rest of this section is about a different lever: making each epoch run faster. Two knobs control that, the device the encoder runs on and the number of subprocesses the dataloader spawns. The next two subsections measure each in turn.
Picking a device¶
When picking hardware for a fit, the practical question is how much faster a GPU makes things compared to plain CPU. To answer it, we ran the same one-epoch fit on full MNIST (70k observations, 784 features) across four devices: the laptop’s CPU and MPS, plus a Modal T4 and an H100. Each device runs with its near-optimal num_workers (2 for CPU and MPS, 8 for T4 and H100), the default batch_size=10000, and the default encoder (133K parameters). The next subsection covers num_workers directly, but for now treat those values as a given. The chart below is the result.
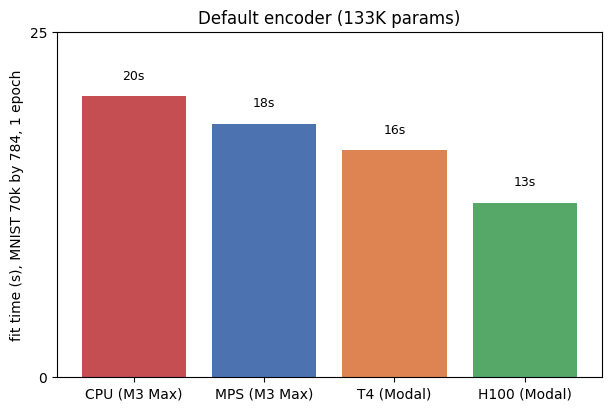
Picking up a GPU does help, but only modestly. CPU is the slowest at about 20 seconds. MPS shaves a couple of seconds off, T4 a bit more, and H100 the most, dropping to about 13 seconds. The improvement is appreciable, however it’s surprising that it falls well short of what neural-network training usually delivers when you graduate to a GPU. A factor of ten or more is typical when a real model moves onto a discrete card. Here even the H100 is only about 1.6x faster than CPU, and the cheap T4 lands within a few seconds of the H100, which makes the price difference hard to justify on this workload.
The reason is that the encoder is small at 133K parameters, so per-step time is dominated by CPU-bound bookkeeping (DataLoader iteration, Lightning callbacks, the optimizer step, the trainer thread) rather than by GPU compute. As evidence, we re-ran the same fit with progressively larger encoders, widening hidden_size and deepening n_hidden_layers to reach 463K, 2M, 5M, and 18M parameters. If the GPU were already the bottleneck, all four devices should slow down by roughly the same factor as the model grows. They do not.
Warning
A larger encoder is not a better one. The bigger models in the next plot exist only to characterize how each device scales with model compute. For real fits, choose the encoder that matches your data. On simple manifolds, a smaller network can produce a cleaner embedding, as the embedding refinement walkthrough shows on the 3-feature Swiss roll.
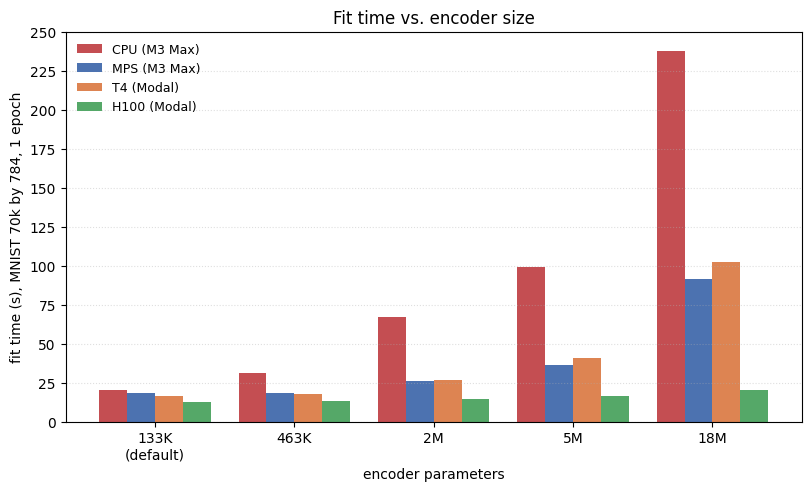
As the encoder grows from 133K to 18M parameters (a 138x increase), fit time grows several-fold on CPU, T4, and MPS, but barely changes on H100, indicative of under-utilization. At the default size, every device pays roughly the same fixed overhead and the four bars are close together. As the encoder grows, the bar that grows least is the one with the most spare compute, aka the most powerful GPU tested (H100).
Ultimately, the takeaway is this: For typical Glass Box UMAP work where the encoder is modestly sized, CPU is enough. And when performance matters, modest speedup can be squeezed out by using a GPU.
Number of data workers¶
Besides picking a device, the only knob you can turn from one fit to the next is num_workers, the number of Python subprocesses the dataloader spawns to pre-stage batches. The setting matters because the encoder is fast: with too few workers, batches arrive too slowly to keep it busy and the device sits idle. With too many workers, you pay scheduling overhead for nothing. The optimum depends on the device, and getting it wrong leaves a multiplicative factor of throughput on the table.
The plot below sweeps num_workers from zero through twelve on full MNIST (70k observations, 784 features) for one training epoch on each of CPU, MPS, T4, and H100.
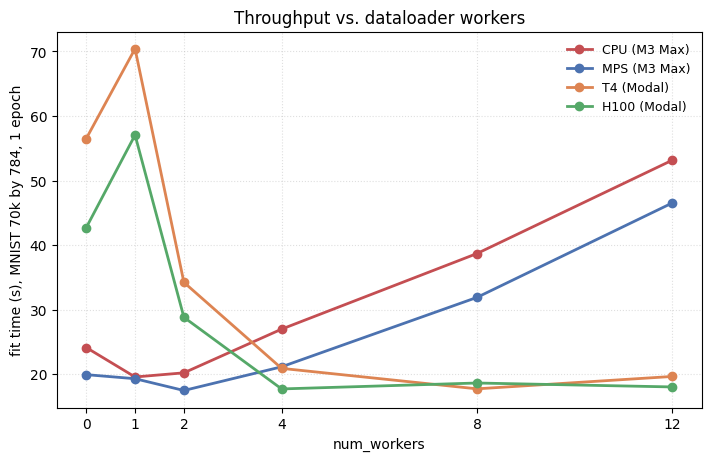
The four lines tell different stories. The two laptop devices (CPU and MPS) sit close together throughout. They do best at 1-2 workers, then climbs steeply as more workers presumably oversubscribe the laptop’s 14 cores.
The two discrete GPUs need more workers to feed them. T4 and H100 both look very slow at 0-1 workers, where the dataloader cannot keep up with the device, then drop sharply between 2-4 workers and flatten by 8. Their hosts have more cores (8 on T4, 32 on H100), so adding workers does not oversubscribe in the same range the laptop does.
Note
On macOS, interrupting a fit with num_workers > 0 (hitting stop in a Jupyter cell partway through training, for example) can leave PyTorch’s shared memory helper subprocess in a broken state. A second fit in the same kernel then fails with
RuntimeError: Please call `iter(combined_loader)` first.
which masks the underlying RuntimeError: Broken pipe from _share_filename_cpu_. The simplest workaround is to restart the kernel after an interrupt. With num_workers=0, or when a fit runs to completion, you can re-run fits freely.
Looking to reproduce these results?
See this README for the scripts and commands.